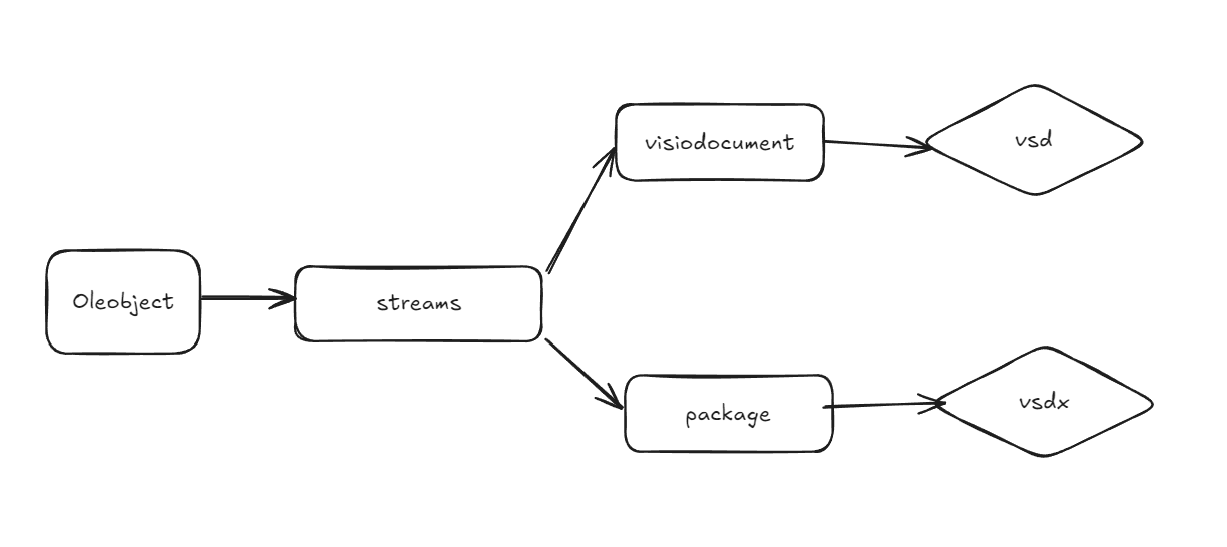
读取 OLE 文件,然后在读取 OLE 文件内所有流 (stream) 和存储 (storage) 的名称 — 这就是 OLE 文件的数据了,需要通过这些数据判断oleObject是不是visio drawing对象对应的文件
1 2
然后需要判断 OLE 文件是不是就是对应的Visio文件
1 2 3 4 5 6 7 8 9 10 11 12
if olefile.isOleFile(file_path): ole = olefile.OleFileIO(file_path) streams = ole.listdir() for stream in streams: if stream[-1].lower().endswith(('.vsd', '.vsdx')): pass if stream[-1].lower() == 'visiodocument': pass if stream[-1].lower()=='package': pass else: print(stream[-1].lower())
对不同分支进行不同的处理即可
1 2 3 4 5 6 7 8 9 10 11 12
if olefile.isOleFile(file_path): ole = olefile.OleFileIO(file_path) streams = ole.listdir() for stream in streams: if stream[-1].lower().endswith(('.vsd', '.vsdx')): pass if stream[-1].lower() == 'visiodocument': pass if stream[-1].lower()=='package': pass else: print(stream[-1].lower())
defextract_first_number(filename): mat = re.search(r'\d+', filename) returnint(mat.group()) if mat else -1
defextract_and_convert_ole_objects(docx_path, output_folder, name_path): try: withopen(name_path, 'r+') as fp: names = fp.readlines() names = [name.strip().replace('/', '').replace('\\', '') for name in names] except Exception as e: logging.error(f"Failed to read {name_path}: {e}") try: with tempfile.TemporaryDirectory() as temp_dir: with ZipFile(docx_path, 'r') as zip_ref: zip_ref.extractall(temp_dir)
embeddings_path = os.path.join(temp_dir, 'word/embeddings') if os.path.exists(embeddings_path):
for index, filename inenumerate(sort_files): file_path = os.path.join(embeddings_path, filename) if filename.lower().endswith('.bin'): output_file_path = os.path.join(output_folder, f"{names[index]}.vsd") logging.info(f"Extracted and converted {filename} to {output_file_path}") if olefile.isOleFile(file_path): ole = olefile.OleFileIO(file_path) streams = ole.listdir() for stream in streams: if stream[-1].lower().endswith(('.vsd', '.vsdx')): data = ole.openstream(stream).read() output_file_path = os.path.join(output_folder, f"{names[index]}{os.path.splitext(stream[-1])[1]}") withopen(output_file_path, 'wb') as f: f.write(data) logging.info(f"Extracted and converted {filename} to {output_file_path}") if stream[-1].lower() == 'visiodocument': data = ole.openstream(stream).read() output_file_path = os.path.join(output_folder, f"{names[index]}.vsd") withopen(output_file_path, 'wb') as f: f.write(data) logging.info(f"Extracted and converted {filename} to {output_file_path}") if stream[-1].lower() == 'package': try: # Read the 'package' stream data data = ole.openstream(stream).read()
# Write the data to a temporary ZIP file with tempfile.NamedTemporaryFile(delete=False, suffix='.zip') as tmp_zip: tmp_zip.write(data) tmp_zip_path = tmp_zip.name
# Extract the temporary ZIP file to a temporary directory with tempfile.TemporaryDirectory() as extract_dir: with ZipFile(tmp_zip_path, 'r') as zip_ref: zip_ref.extractall(extract_dir)
# Create a new ZIP archive from the extracted directory # output_file_path = os.path.join(output_folder, f"{names[index]}.vsd") vsdx_file_name = os.path.join(output_folder, f"{names[index]}.vsdx") shutil.make_archive(vsdx_file_name.rstrip('.vsdx'), 'zip', extract_dir) shutil.copy(f"{vsdx_file_name[:-5]}.zip", vsdx_file_name)
# Log the success message logging.info(f"Extracted and converted {filename} to {vsdx_file_name}")
# Clean up the temporary ZIP file os.remove(tmp_zip_path) except Exception as e: logging.error(f"Failed to process 'package' stream in {filename}: {e}") ole.close() else: logging.warning(f"{filename} is not an OLE file.") else: logging.warning(f"No embeddings found in {docx_path}.") except Exception as e: logging.error(f"Failed to extract and convert objects from {docx_path}: {e}")
for root, dirs, files in os.walk(input_folder): for file in files: base_name, ext = os.path.splitext(file) if ext.lower() in ('.doc', '.docx'): input_file_path = os.path.join(root, file) output_subfolder = os.path.join(output_folder, base_name)